

1. 数据结构
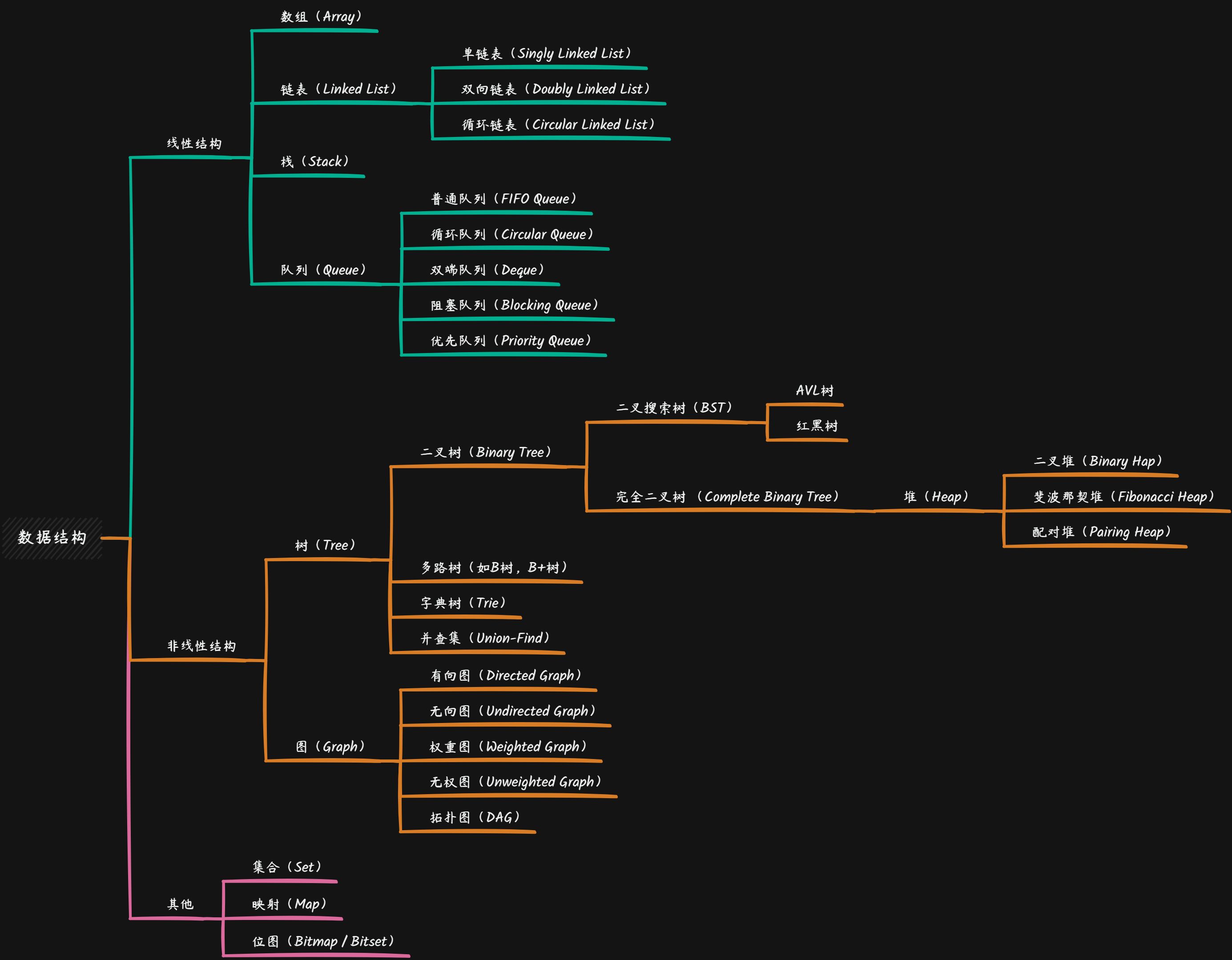
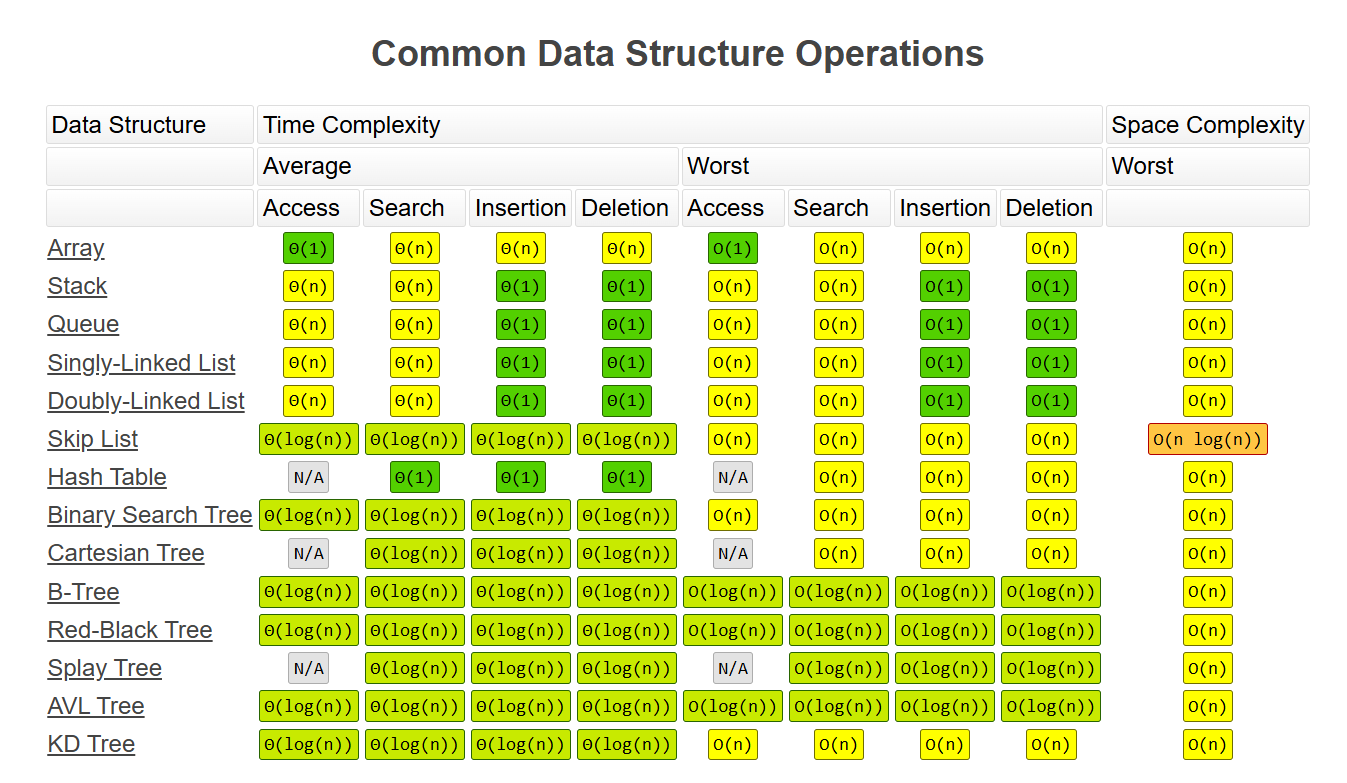
1.1. 线性结构
1.1.1. 数组
结构图
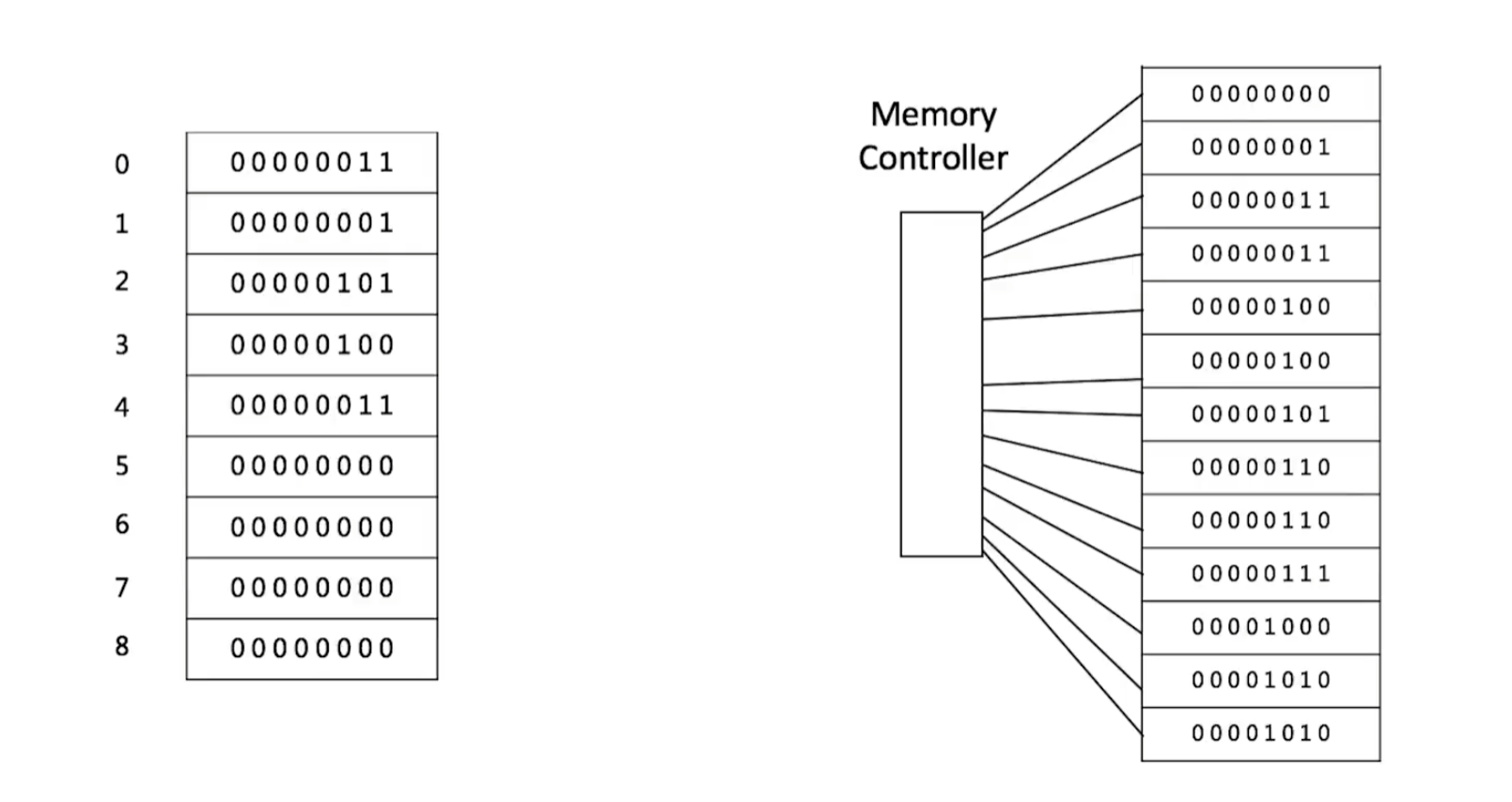
内存中连续存储,可随机访问。常见操作
package datastructures.linear.array;
/**
* 原始数组结构,处理插入和删除
*/
public class RawArray {
/**
* 数组插入元素,本地插入。
*
* @param array 数组
* @param index 插入数据的下标
* @param value 插入数据的值
* @param size 当前数组有效元素的个数
*/
public void insert(int[] array, int index, int value, int size) {
if (size >= array.length || index < 0 || index > size) {
throw new IllegalArgumentException("插入失败:索引非法或数组已满");
}
for (int i = size - 1; i >= index; i--) {
array[i + 1] = array[i];
}
array[index] = value;
}
/**
* 数组删除目标元素,本地删除。
*
* @param a 数组
* @param index 下表
* @param size 当前数组有效元素个数
*/
public void delete(int[] a, int index, int size) {
if (index < 0 || index >= size) {
throw new IllegalArgumentException("删除失败:索引非法");
}
for (int i = index; i < size; i++) {
a[i] = a[i + 1];
}
}
public static void main(String[] args) {
int[] array = {0, 1, 2, 3, 4, 5, 6, 0, 0, 0, 0};
RawArray ra = new RawArray();
ra.insert(array, 4, 10, 7);
for (int i = 0; i < array.length; i++) {
System.out.println(array[i]);
}
System.out.println("--------------");
ra.delete(array, 3, 8);
for (int i = 0; i < array.length; i++) {
System.out.println(array[i]);
}
}
}
误区纠正:自己写的时候,没有传入size,结果代码始终有问题。我原来的理解是,使用数组的长度 array.length 就可以了。但在移动数组时,会出现越界的情况。经过调查,我明白了,必须在代码中明确的标出当前已经使用了多少个元素,即size。并用size作为循环的边界。在ArrayList中,也是如此,它声明了实例变量 size,是核心属性之一。
package datastructures.linear.array;
import java.util.ArrayList;
public class UseArrayList {
public static void main(String[] args) {
ArrayList<Integer> arrayList = new ArrayList<>();
arrayList.add(0);
arrayList.add(3, 10); // 当列表中没有索引为2的数就插入索引为3的数时会报错 IndexOutOfBoundsException
arrayList.add(1, 5);
System.out.println("插入后:" + arrayList);
arrayList.remove(0);
System.out.println("删除后:" + arrayList);
}
}
// 源码片段(简化自 java.util.ArrayList):
Object[] elementData; // 底层数组
int size; // 实际存储元素的个数
public boolean add(E e) {
ensureCapacity(size + 1);// 自动扩容逻辑,这里的扩容扩的是已经使用的元素个数,而不是数组大小。
elementData[size++] = e;
return true;
}1.1.2. 链表
1.1.2.1. 单链表
结构图
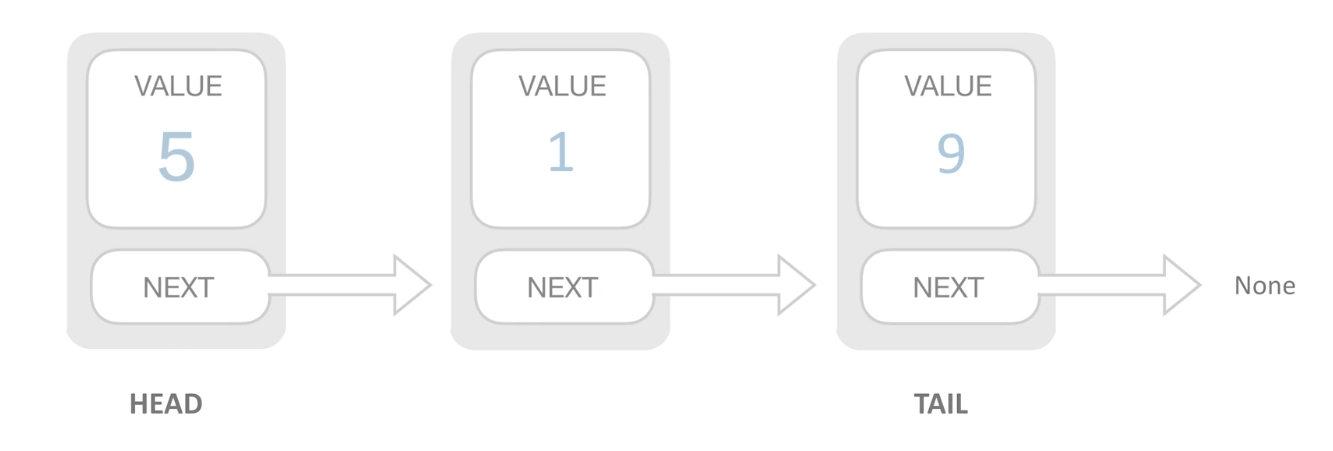
代码表示
class Node {
int val; // 数据
Node next; // 指向下一个节点
public Node(int val) {
this.val = val;
}
}常见操作
package datastructures.linear.linkedlist;
public class MyLinkedList {
class Node {
int val;
Node next;
public Node(int val) {
this.val = val;
}
}
private Node head; // 头节点
public void insert(int val) {
Node newNode = new Node(val);
if (head == null) {
head = newNode;
}
Node cur = head;
while (cur.next != null) {
cur = cur.next;
}
cur.next = newNode;
}
public void deleteAt(int index) {
if (head == null) return;
if (index == 0) {
head = head.next;
return;
}
Node cur = head;
for (int i = 0; i < index - 1 && cur != null; i++) {
cur = cur.next;
}
if (cur == null || cur.next == null) {
throw new IndexOutOfBoundsException("删除位置不合法");
}
cur.next = cur.next.next;
}
public void delete(Node node) {
if (head == node) {
head = head.next;
return;
}
Node cur = head;
while (cur.next != null && cur.next != node) {
cur = cur.next;
}
if (cur.next == node) {
cur.next = node.next;
}
}
}
1.1.2.2. 双向链表
结构图
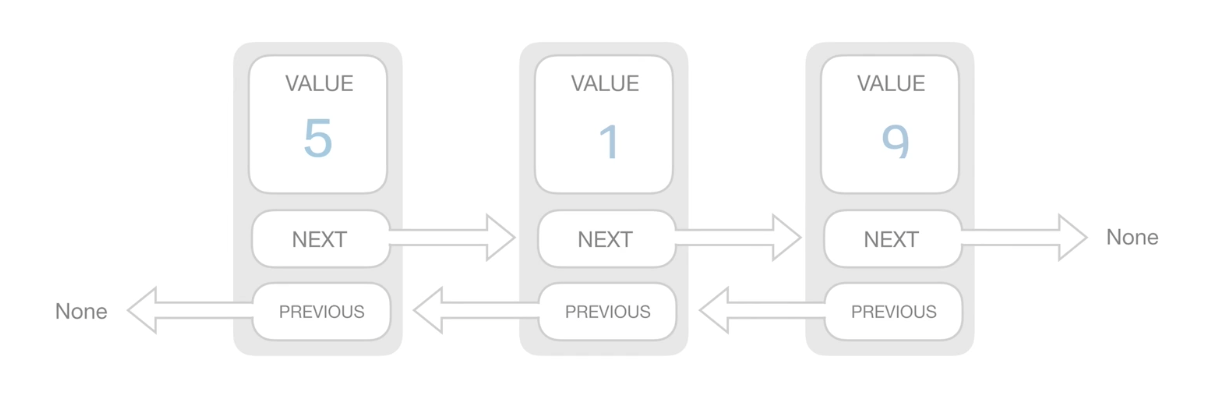
代码表示
class DNode {
int val;
DNode prev, next;
public DNode(int val) {
this.val = val;
}
}常见操作
1.1.2.3. 循环链表
1.1.2.4. 对比
1.1.3. 栈和队列
数据结构
├── Stack(栈)【LIFO】
│ └── 实现方式:
│ ├── 使用 Deque(推荐,如 ArrayDeque)
│ └── 老的 Stack 类(继承 Vector,不推荐)
│
├── Queue(队列)【FIFO】
│ ├── 普通队列
│ │ └── 实现类:
│ │ ├── LinkedList
│ │ └── ArrayDeque
│ ├── 优先队列(PriorityQueue)【按优先级出队】
│ └── 并发队列(ConcurrentLinkedQueue 等)
│
└── Deque(双端队列)【双向进出】
├── 可模拟 Stack(使用 push/pop)
├── 可模拟 Queue(使用 offerLast/pollFirst)
└── 实现类:
├── ArrayDeque(推荐)
└── LinkedList(功能全但性能略差)
继承关系
java.util.Collection (接口)
├── List (接口) [有序、可重复]
│ ├── ArrayList
│ ├── LinkedList
│ └── Vector
│ └── Stack(不推荐)
│
├── Set (接口) [无序、不可重复]
│ ├── HashSet
│ │ └── LinkedHashSet
│ └── SortedSet (接口)
│ └── NavigableSet (接口)
│ └── TreeSet
│
└── Queue (接口) [FIFO]
├── Deque (接口)
│ ├── LinkedList
│ └── ArrayDeque
├── PriorityQueue
└── BlockingQueue (接口,来自 java.util.concurrent)
└── LinkedBlockingQueue 等
1.1.3.1. 栈
Stack - First In Last Out(FILO)
Java中推荐使用 ArrayDeque
Stack 继承自 Vector,性能和线程安全机制不现代,不推荐使用。官方推荐用 Deque 来实现栈功能(如 ArrayDeque),性能更好。
结构图
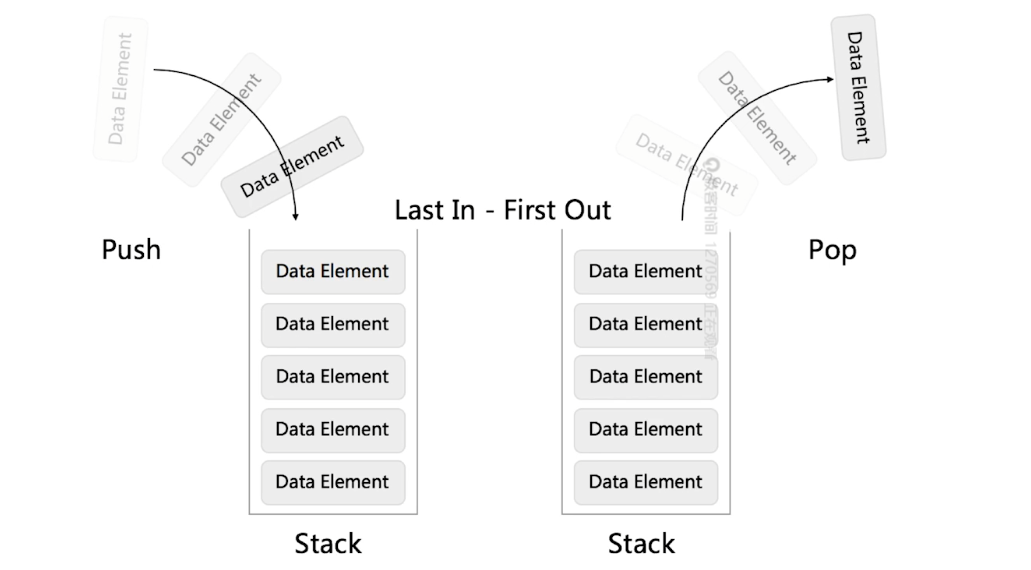
常见操作
代码展示
import java.util.Deque;
import java.util.ArrayDeque;
public class StackExample {
public static void main(String[] args) {
Deque<Integer> stack = new ArrayDeque<>();
stack.push(10); // 入栈
stack.push(20);
System.out.println(stack.peek()); // 查看栈顶 -> 20
System.out.println(stack.pop()); // 出栈 -> 20
System.out.println(stack.isEmpty()); // 是否为空 -> false
System.out.println(stack.size()); // 元素数量 -> 1
}
}1.1.3.2. 队列
Queue - FIrst In First Out(FIFO)
Array or Doubly Linked List
结构图
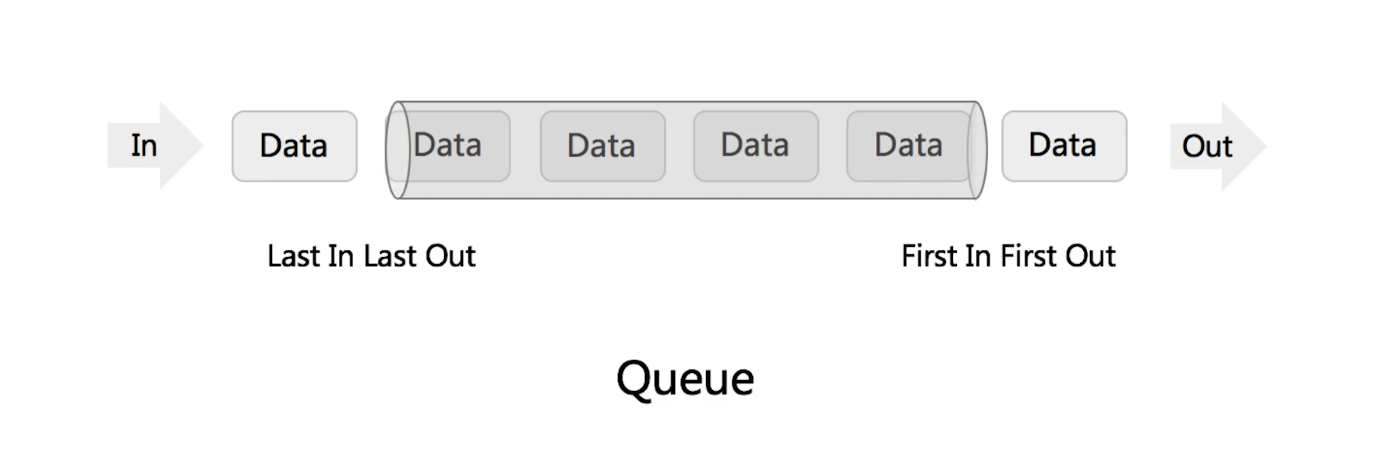
常见操作
代码展示
import java.util.Queue;
import java.util.LinkedList;
public class QueueExample {
public static void main(String[] args) {
Queue<Integer> queue = new LinkedList<>();
queue.offer(1); // 入队
queue.offer(2);
System.out.println(queue.peek()); // 查看队头 -> 1
System.out.println(queue.poll()); // 出队 -> 1
System.out.println(queue.isEmpty()); // 是否为空 -> false
System.out.println(queue.size()); // 剩余元素个数 -> 1
}
}1.1.4. 优先队列
PriorityQueue - 优先队列
正常入、按照优先级出
1.1.4.1. 堆(heap)
定义和性质
结构性质:必须是完全二叉树,除了最后一层外,每层节点必须是满的。
堆序性质:父节点和子节点之间必须满足大小关系
最小堆(Min-Heap):每个父节点 ≤ 其左右子节点
最大堆(Max-Heap):每个父节点 ≥ 其左右子节点
堆不要求兄弟节点之间有大小关系
局部有序:只能保证堆顶全局最大/最小。
实现机制
补充说明:
Binary Heap(常用):Java 中
PriorityQueue默认使用小顶二叉堆。Fibonacci Heap:在某些图算法(如 Dijkstra, Prim)中理论上具有优势。
Pairing Heap:性能类似 Fibonacci Heap,且实现简单。
D-ary Heap:通常用在需要减少“堆化次数”的系统中,例如网络包处理。
Skew / Leftist / Binomial:适合频繁合并场景。
1.1.4.2. 优先队列(PriorityQueue)
Java中的常见实现
PriorityQueue数据结构
Java 中,实现 PriorityQueue 用的是完全二叉树,而底层是一个数组。
逻辑上:我们认为它是一个“完全二叉树”结构,用来维持堆的顺序关系(父节点 ≥ 或 ≤ 子节点)。
实际实现上:用 数组(Array) 来高效地表示这个完全二叉树。
在数组中,结点与子结点的位置有确定的映射关系。假设根节点索引为 0,那么对于任意节点索引 i:
因此:
不需要使用指针/引用;
插入、删除、访问父子节点非常高效;
内存连续,CPU 缓存友好。
常见操作
代码
PriorityQueue 的常见操作
import java.util.PriorityQueue;
public class PriorityQueueExample {
public static void main(String[] args) {
// 默认最小堆
PriorityQueue<Integer> pq = new PriorityQueue<>();
// 插入元素
pq.add(10);
pq.add(5);
pq.add(20);
System.out.println("队顶元素 peek(): " + pq.peek()); // 输出 5
// 取出并删除最小元素
System.out.println("弹出元素 poll(): " + pq.poll()); // 输出 5
System.out.println("再次查看队顶: " + pq.peek()); // 输出 10
// 删除指定元素
pq.remove(20);
// 判空
System.out.println("是否为空: " + pq.isEmpty());
// 元素个数
System.out.println("元素个数: " + pq.size());
// 清空
pq.clear();
}
}
Java 中的 PriorityQueue 默认是最小堆,最大堆需要使用 Comparator 构造。
import java.util.*;
public class MaxHeapExample {
public static void main(String[] args) {
PriorityQueue<Integer> maxHeap = new PriorityQueue<>(Comparator.reverseOrder());
maxHeap.add(3);
maxHeap.add(1);
maxHeap.add(5);
while (!maxHeap.isEmpty()) {
System.out.println(maxHeap.poll()); // 输出顺序:5, 3, 1
}
}
}1.2. 非线性结构
1.2.1. 树
1.2.1.1. 二叉搜索树
public class TreeNode {
public int val;
public TreeNode left;
public TreeNode right;
public TreeNode (int val) {
this.val = val;
this.left = null;
this.right = null;
}
}1.2.1.1.1. 二叉树遍历
前序(Pre-Order):根-左-右
中序(In-Order):左-根-右
后序(Post-Order):左-右-根
class Traversal {
public void preOrder(TreeNode node) {
if (node == null) return;
System.out.print(node.val + " ");
preOrder(node.left);
preOrder(node.right);
}
public void inOrder(TreeNode node) {
if (node == null) return;
inOrder(node.left);
System.out.print(node.val + " ");
inOrder(node.right);
}
public void postOrder(TreeNode node) {
if (node == null) return;
postOrder(node.left);
postOrder(node.right);
System.out.print(node.val + " ");
}
}
1.2.1.2. AVL和红黑树
1.2.1.3. 字典树 Trie
Trie 树的数据结构
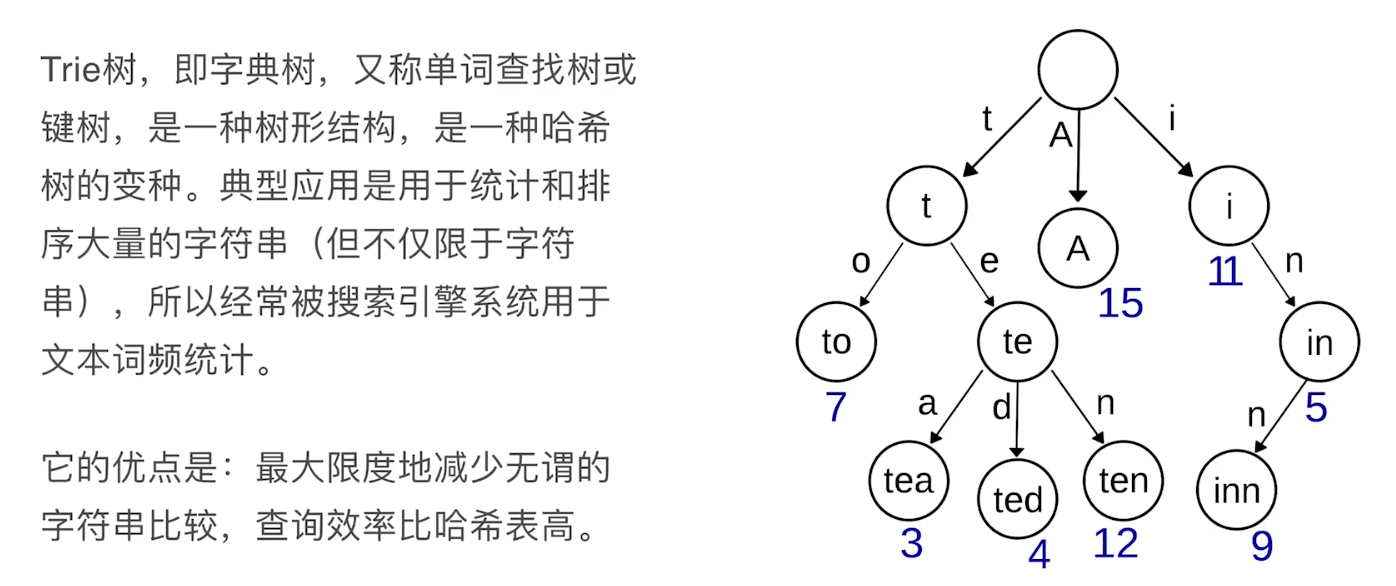
字典树的真实结构如下,它的每一个节点都是一个数组,数组的长度相同: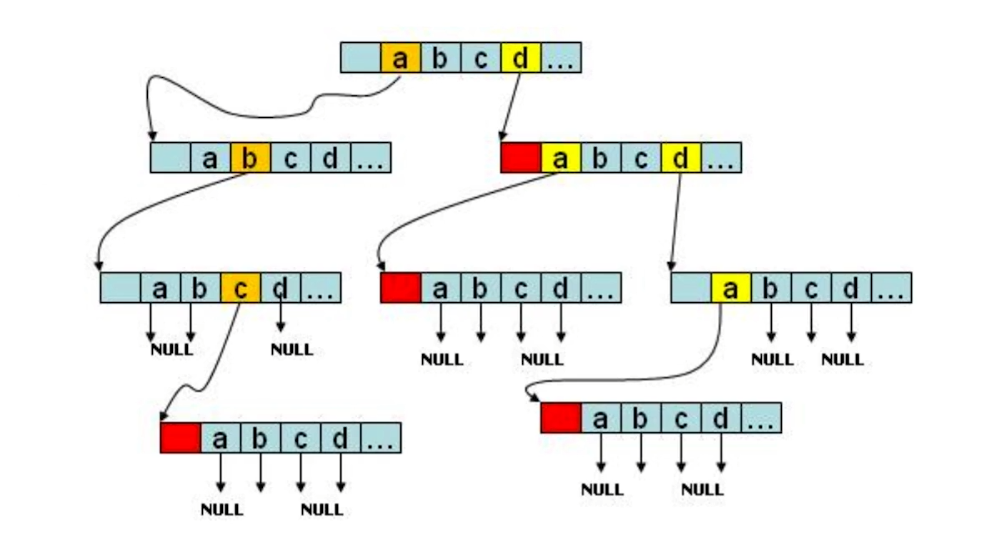
Trie 树的核心思想
空间换时间。
利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。Trie 树的基本性质
根节点不包含字符,除根节点外每一个节点都只包含一个字符。
从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
每个节点的所有子节点包含的字符都不相同。
代码
package trie;
public class Trie {
static final int ALPHABET_SIZE = 26;
private TrieNode root = new TrieNode();
/**
* 插入单词
*/
public void insert(String word) {
if (word.isEmpty()) {
return;
}
TrieNode node = root;
for (char c : word.toCharArray()) {
int i = c - 'a';
if (node.children == null) {
node.children = new TrieNode[ALPHABET_SIZE];
}
node = node.children[i];
}
node.isEndOfWord = true;
}
/**
* 搜索单词是否存在
*/
public boolean search(String word) {
TrieNode trieNode = searchNode(word);
return trieNode != null && trieNode.isEndOfWord;
}
private TrieNode searchNode(String str) {
TrieNode node = root;
for (char c : str.toCharArray()) {
int i = c - 'a';
if (node.children == null) {
return null;
}
node = node.children[i];
}
return node;
}
class TrieNode {
TrieNode[] children = new TrieNode[ALPHABET_SIZE];
boolean isEndOfWord = false;
}
}
1.2.2. 图
1.3. 其他
1.3.1. 哈希表
1.3.1.1. 哈希原理
什么是哈希
哈希是一种通过函数(Hash Function)将任意大小的输入映射为固定长度的输出的方式。
举例:
输入字符串:"Tom" → 哈希函数 → 输出:378402
这个输出称为:哈希值(Hash Code)
哈希的主要用途
快速查找:通过哈希值可以快速定位数据(比如哈希表)
数据校验:如文件完整性校验(如 MD5, SHA-256)
分布式分片:哈希值用于数据分区
去重:将数据转为哈希值快速判断是否重复
哈希冲突
不同的输入可能产生相同的哈希值,这称为哈希冲突。
例如:
"cat" → 123456
"tac" → 123456
在哈希表结构中,必须通过链表或树结构来解决冲突。
1.3.1.2. 哈希表
哈希表是以数组为底层结构 + 哈希函数映射,实现接近 O(1) 的插入/查找效率。
1.3.1.3. Java中的哈希结构与树结构
1.3.1.4. HashMap 工作机制简述
put
执行流程:hashCode():计算键的哈希值扰动函数优化分布找桶位置:
hash % 数组长度冲突:
没冲突:直接插入
冲突:链表插入(长度>8变红黑树)
查询时也只需遍历一个桶中的链表或树 → 快速查找
1.3.1.5. TreeMap 工作机制简述
TreeMap 是基于 红黑树 实现的映射容器。
特性:
键是有序的
插入/删除/查询时间复杂度:
O(log n)可以用自定义
Comparator控制顺序
TreeMap<String, Integer> map = new TreeMap<>();
map.put("apple", 3);
map.put("banana", 1);
map.put("cat", 2);键自动升序排列(apple, banana, cat)
1.3.1.6. HashSet & TreeSet 是 Map 的简化封装
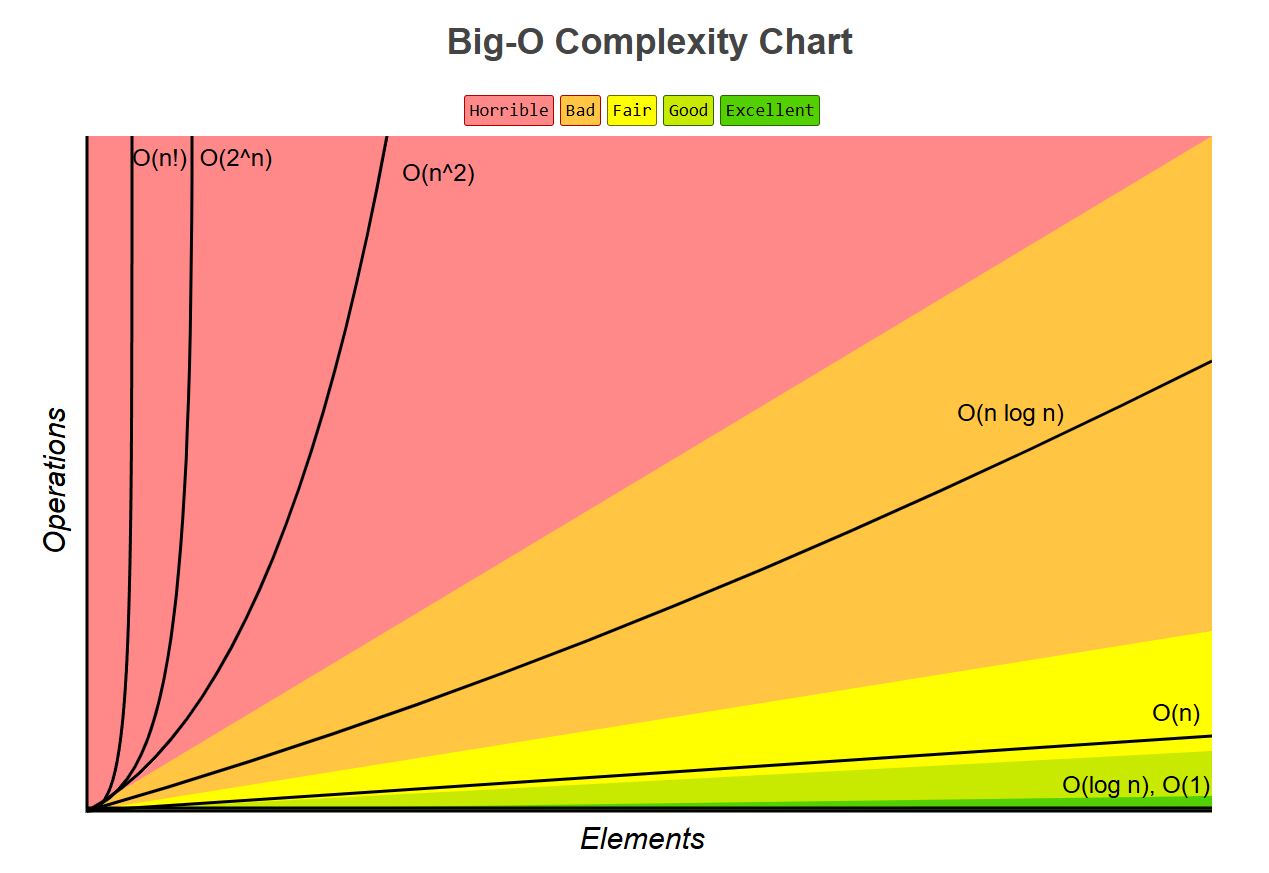
2. 算法
2.1. 基础算法
2.1.1. 排序
2.1.1.1. 归并排序
2.1.1.2. 快速排序
2.1.2. 查找
2.1.2.1. 顺序查找
2.1.2.2. 二分查找
条件
单调递增或者递减(Sorted)
存在上下界(Bounded)
能够通过索引访问(Accessible by index)
代码
public class BinarySearch {
/**
* 二分查找目标索引
* 假定 a 是已经排序的
*/
public int binarySearch(int[] a, int target) {
int lo = 0, hi = a.length - 1;
while (lo <= hi) {
int mid = (hi - lo) / 2 + lo;
if (a[mid] == target) {
return mid;
} else if (a[mid] < target) {
lo = mid + 1;
} else {
hi = mid - 1;
}
}
return -1;
}
}2.1.2.3. 哈希查找
2.1.2.4. 二叉搜索树
2.1.2.5. 平衡搜索树
2.1.2.6. 广度优先搜索(Breadth-First-Search)
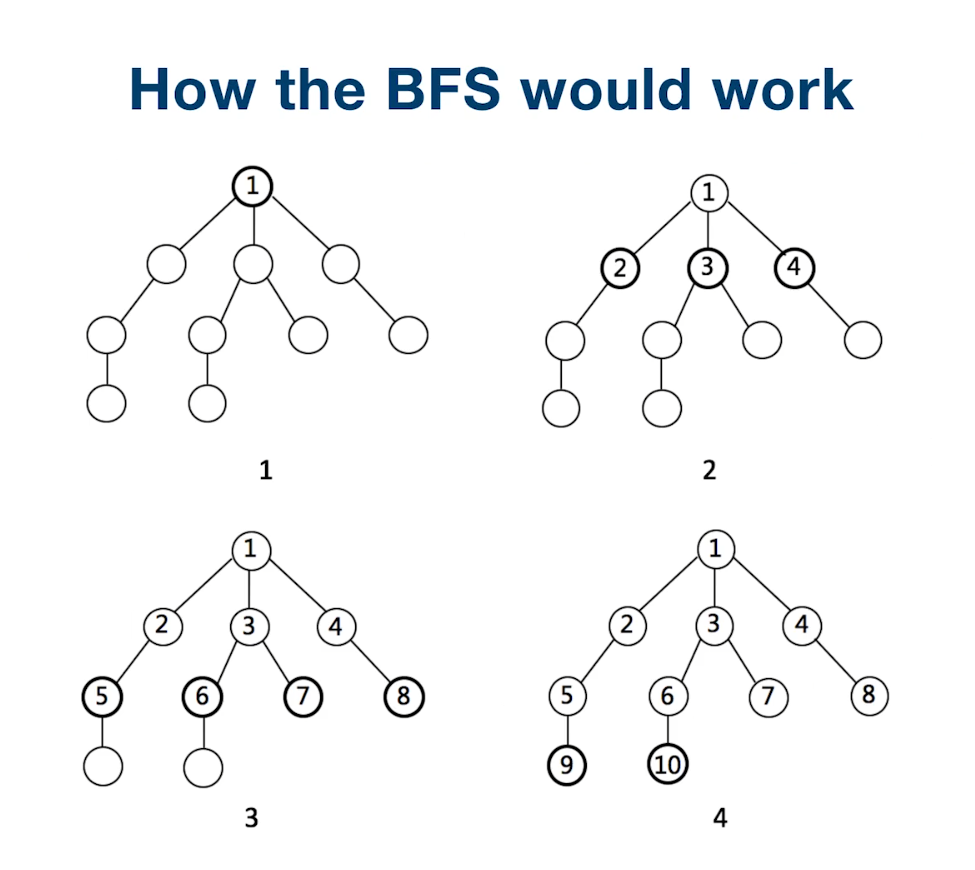
import java.util.*;
public class Solution {
public void bfs(int start, Map<Integer, List<Integer>> graph) {
Queue<Integer> queue = new LinkedList<>();
Set<Integer> visited = new HashSet<>();
queue.offer(start);
visited.add(start);
while (!queue.isEmpty()) {
int node = queue.poll();
System.out.println("访问节点: " + node);
for (int neighbor : graph.getOrDefault(node, new ArrayList<>())) {
if (!visited.contains(neighbor)) {
queue.offer(neighbor);
visited.add(neighbor);
}
}
}
}
}Queue<Integer> queue = new LinkedList<>();
Set<Integer> visited = new HashSet<>();
queue.offer(start);
visited.add(start);
while (!queue.isEmpty()) {
int size = queue.size(); // 当前这一层的节点数量
for (int i = 0; i < size; i++) {
int node = queue.poll(); // 访问当前层的节点
for (int neighbor : graph.getOrDefault(node, new ArrayList<>())) {
if (!visited.contains(neighbor)) {
queue.offer(neighbor); // 下一层
visited.add(neighbor);
}
}
}
// 当前层访问完毕,queue 只剩下一层的所有节点
}
2.1.2.7. 深度优先搜索(Depth-First-Search)
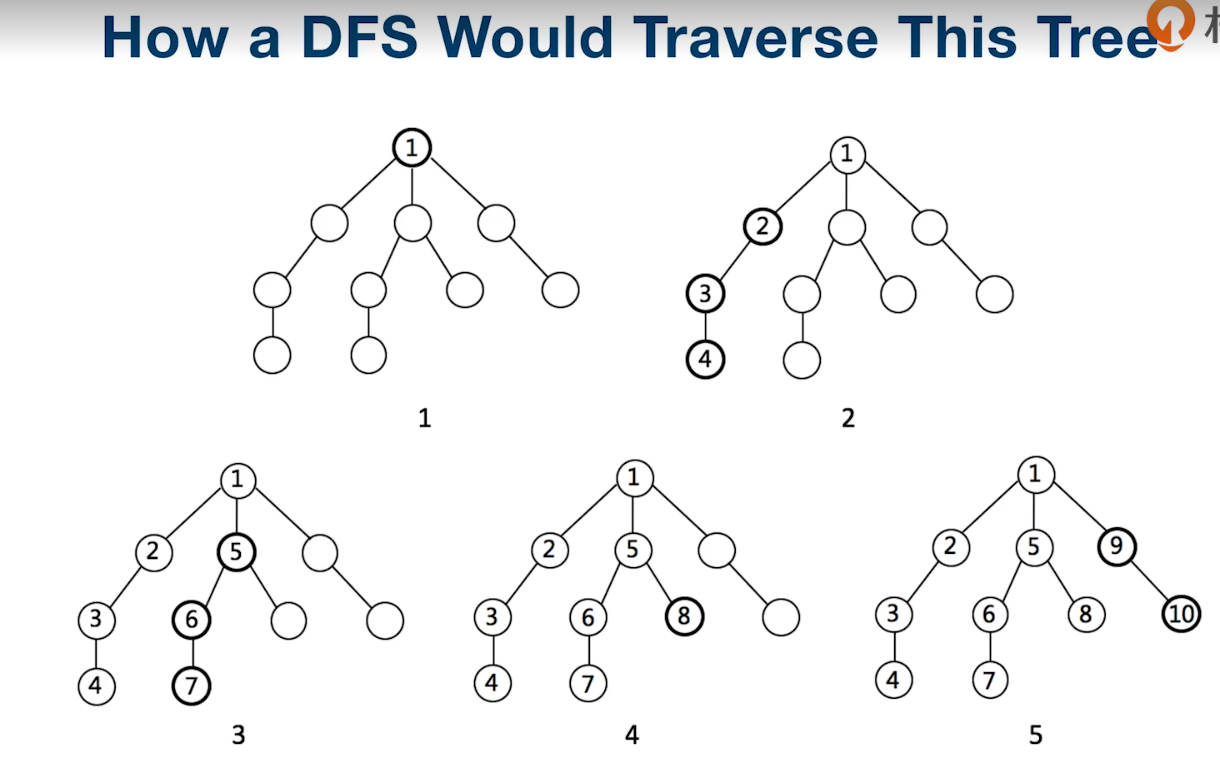
import java.util.*;
public class Solution {
public void dfs(int node, Map<Integer, List<Integer>> graph, Set<Integer> visited) {
if (visited.contains(node)) return;
visited.add(node);
System.out.println("访问节点:" + node);
for (int neighbor : graph.getOrDefault(node, new ArrayList<>())) {
dfs(neighbor, graph, visited);
}
}
public void runDFS(int start, Map<Integer, List<Integer>> graph) {
Set<Integer> visited = new HashSet<>();
dfs(start, graph, visited);
}
}2.2. 算法范式
2.2.1. 递归(Recursion)
void recursion(参数) {
// 1. 终止条件(Base Case)
if (满足终止条件) {
return;
}
// 2. 当前层处理逻辑(当前状态的操作)
// ...
// 3. 进入下一层(递归调用)
recursion(变化后的参数);
// 4. 如果需要,恢复状态(回溯时使用)
// ...
}
递归三要素:
2.2.2. 分治(Divide and Conquer)
ReturnType divideAndConquer(ProblemType problem) {
// 1. 终止条件(不能再分)
if (problem规模足够小) {
return 直接解决;
}
// 2. 拆分为子问题
ProblemType subProblem1 = 拆分方式1(problem);
ProblemType subProblem2 = 拆分方式2(problem);
// 可以有多个子问题
// 3. 递归解决子问题
ReturnType result1 = divideAndConquer(subProblem1);
ReturnType result2 = divideAndConquer(subProblem2);
// 4. 合并子问题结果
ReturnType result = merge(result1, result2);
return result;
}
2.2.3. 动态规划(Dynamic Programming)
2.2.3.1. 基本知识
动态规划是将复杂问题分解成子问题,利用子问题最优解构造整体最优解。
核心要素:最优子结构 + 重叠子问题
状态:问题的某一阶段的“局部情况”描述
状态的定义:opt[n]:常用来表示“规模为 n 的问题的最优解”(opt = optimal)。
dp[n]:一般表示“规模为 n 的子问题的解”(Dynamic Programming)。
状态转移方程:由子状态计算当前状态的方法
当前状态的最优解,可以通过之前已计算的状态的最优解,经过某种“选择”操作,推导得到。
状态转移方程:opt[n] = best_of(opt[n-1], opt[n-2], ...)边界条件(Base Case):DP 初始值,最小子问题解
记忆化(Memoization)vs 迭代(Tabulation):递归 + 记忆化 -> 递推
2.2.3.2. 能否用DP
满足以下三个特征,就可以考虑用 DP:
问题可以分解成“子问题”
比如整体问题的答案依赖于子问题的解。
例:爬楼梯问题(爬第n阶 = 爬n-1 + 爬n-2)
子问题有“重叠”
同一个子问题在递归/搜索中被多次计算。
例:斐波那契数列,f(n) = f(n-1) + f(n-2),很多重复计算。
问题有“最优子结构”
当前状态的最优解依赖于之前某个状态的最优解。
例:背包问题,当前容量的最优选择依赖于更小容量的选择。
2.2.3.3. 解题思路
明确问题的“最优子结构”
复杂问题能分解成规模更小的子问题。
子问题的最优解能组合成原问题的最优解。
找出“状态”
定义“状态”:用一个或多个变量表示当前子问题的规模或特征。
每个状态代表一个子问题。
确定“状态转移方程”
找出从子状态到当前状态的关系,即“dp方程”。
这通常是表达当前状态的最优值是如何通过之前状态的最优值计算得来的。
确定“边界条件”或“初始状态”
明确最小子问题的答案(base case),作为状态转移的起点。
选择计算顺序(自顶向下还是自底向上)
自顶向下:带备忘录的递归(记忆化递归)。
自底向上:循环计算所有状态,填表。
根据需要,设计状态压缩或空间优化
例如,一维数组代替二维数组,减少空间复杂度。
2.2.3.4. 常见模板
一维线性DP(例如最大子序和、斐波那契数列)
int n = nums.length;
int[] dp = new int[n];
dp[0] = nums[0];
for (int i = 1; i < n; i++) {
dp[i] = Math.max(nums[i], dp[i-1] + nums[i]);
}
return dp[n-1];二维DP(例如最长公共子序列、矩阵路径)
int m = s1.length(), n = s2.length();
int[][] dp = new int[m+1][n+1];
for (int i = 1; i <= m; i++) {
for (int j = 1; j <= n; j++) {
if (s1.charAt(i-1) == s2.charAt(j-1)) {
dp[i][j] = dp[i-1][j-1] + 1;
} else {
dp[i][j] = Math.max(dp[i-1][j], dp[i][j-1]);
}
}
}
return dp[m][n];背包类DP
for (int i = 1; i <= n; i++) {
for (int j = 0; j <= capacity; j++) {
if (weight[i] > j) {
dp[i][j] = dp[i-1][j];
} else {
dp[i][j] = Math.max(dp[i-1][j], dp[i-1][j-weight[i]] + value[i]);
}
}
}状态压缩(一维滚动数组优化)
int[] dp = new int[capacity+1];
for (int i = 1; i <= n; i++) {
for (int j = capacity; j >= weight[i]; j--) {
dp[j] = Math.max(dp[j], dp[j - weight[i]] + value[i]);
}
}记忆化递归(自顶向下)
Map<Integer, Integer> memo = new HashMap<>();
public int dfs(int state) {
if (memo.containsKey(state)) return memo.get(state);
// 计算状态结果
memo.put(state, result);
return result;
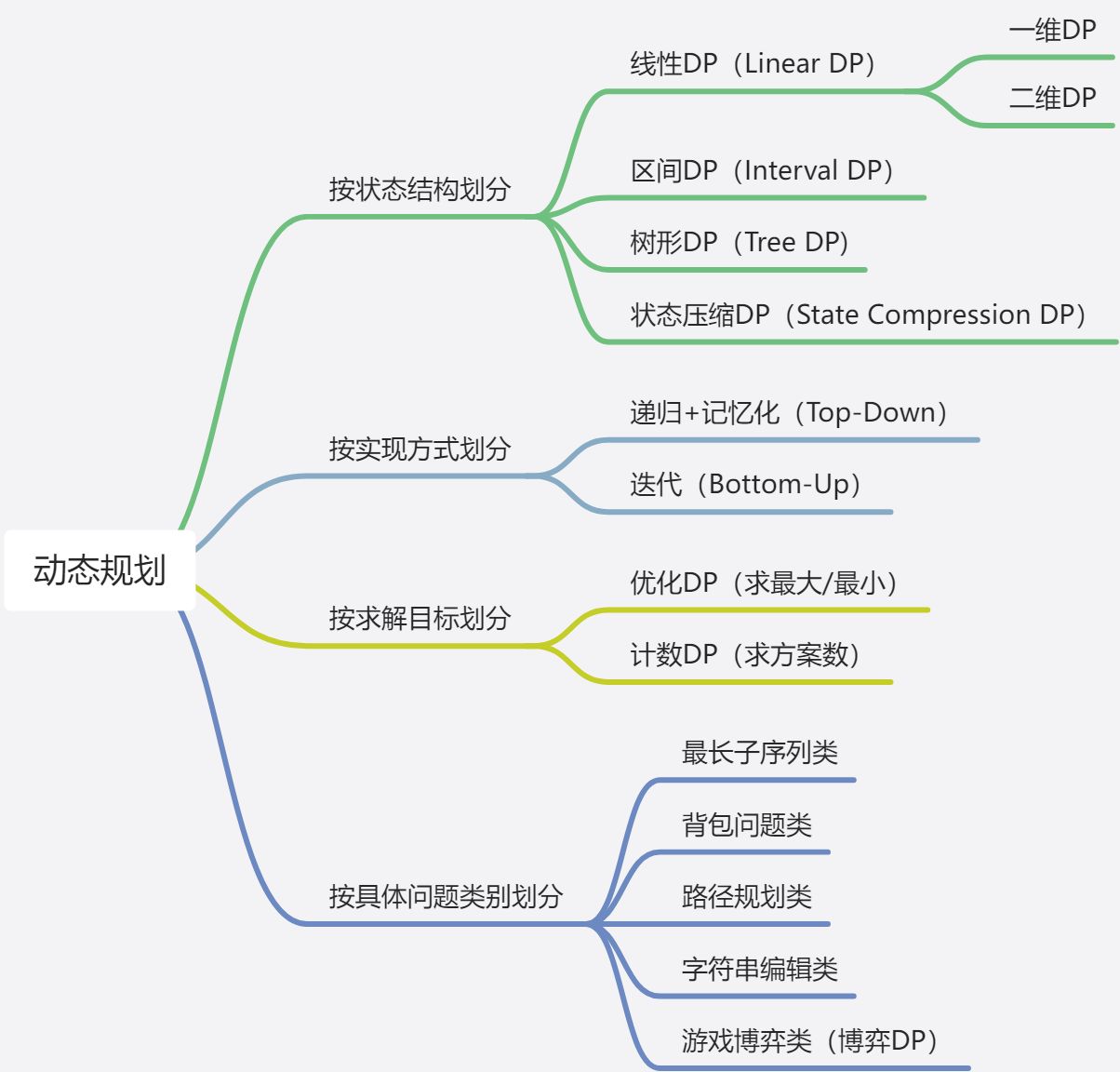
}2.2.3.5. 分类
2.2.4. 贪心算法(Greedy Algorithm)
贪心算法:在对问题求解时,总是做出在当前看来最好的选择。
使用场景:
简单地说,问题能够分解成子问题解决,子问题的最优解能地推到最终问题的最优解。这种子问题最优解成为最优子结构。
贪心算法与动态规划的不同在于它对每个子问题的解决方案都做出选择,不能回退。动态规划则会保存以前的运算结果,并根据以前的结果对当前进行选择,有回退功能。
2.2.5. 回溯算法(Backtracking)
3. 优化技巧
3.1. 位运算
3.1.1. 位运算介绍
程序中的所有数在计算机内存中都是以二进制的形式存储的。位运算说穿了,就是直接对整数在内存中的二进制位进行操作。比如,and 运算本来是一个逻辑运算符,但整数与整数之间也可以进行and运算。举个例子,6 的二进制是 110,11 的二进制是 1011,那么 6 and 11 的结果就是 2,它是二进制对应位进行逻辑运算的结果(0表示False,1表示True,空位都当0处理):
110 AND 1011 --> 0010(b) --> 2(d)由于位运算是直接对内存数据进行操作,不需要转成十进制,因此处理速度非常快。
3.1.2. 位运算常用操作
XOR - 异或
异或:相同为0,不同位1。也可用【不进位加法】来理解。
异或操作的一些特点:
x ^ 0 = x
x ^ 1s = ~x // 1s = ~0
x ^ (~x) = 0
a ^ b = c => a ^ c = b, b ^ c = a // 交换
a ^ b ^ c = a ^ ( b ^ c) = ( a ^ b) ^ c
3.1.3. 位运算的应用
3.1.3.1. 经典应用
判断奇偶
if ((n & 1) == 1) // 奇数
if ((n & 1) == 0) // 偶数快速乘除以 2 的幂
n << 1 // 等价于 n * 2
n >> 1 // 等价于 n / 2(取整)交换两个数(不使用临时变量)
a = a ^ b;
b = a ^ b;
a = a ^ b;只出现一次的数字
int res = 0;
for (int num : nums) {
res ^= num;
}x & 1 == 1 or == 0判断奇偶x = x & ( x - 1)=> 清零最低位的 1x & -x=> 得到最低位的 1
3.1.3.2. 更为复杂的位运算操作
将
x最右边的n位清零 -x & (~0 << n)获取
x的第n位值(0或者1) -( x >> n ) & 1获取
x的第 n 位的幂值 -x & ( 1 << ( n - 1 ) )仅将第
n位置为 1 -x | ( 1 << n )仅将第
n位置为 0 -x & ( ~ ( 1 << n ) )将 x 最高位至第
n位(含)清零 -x & ( ( 1 << n ) - 1 )将第
n位至第 0 位(含)清零 -x & ( ~ ( ( 1 << ( n + 1 ) ) - 1
评论